
前言
本文讲解Google在2019年发表的论文BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding 。从标题可以看出,该论文基于Transformer模型,提出了一款用于语言理解的预训练模型,并在GLUE, SQuAD等nlp任务中都取得了很好的效果。该模型的创新点实际上不在于模型结构,而在于预训练的方法。以下围绕这两方面都进行一些讲解。
模型结构
总体框图
首先最好还是先理解一下Transfomer,这是BERT模型的基础所在。简而言之,Transfomer包含N个编码器和解码器。编码器将输入序列编码成带有全局新的特征序列,解码器将编码器的特征序列解码成预测结果。BERT使用的正是其中的编码器,模型如下所示。
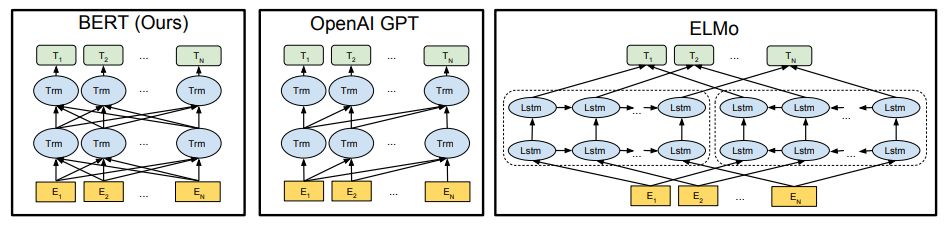
注意:并不是一个Tm代表一个Transformer,可以看成一行Tm表示一个Transformer的编码器,而编码器也不是两层可以有多层。那么,输入序列送入BERT后,最后一层Tm将对每一个输入token都生成一个新的特征序列,而T则表示任务,一般都是用全连接层来完成分类任务。另外用来对比的是,与GPT是单向的Transformer连接,ELMo是双向的LSTM连接。
Embedding
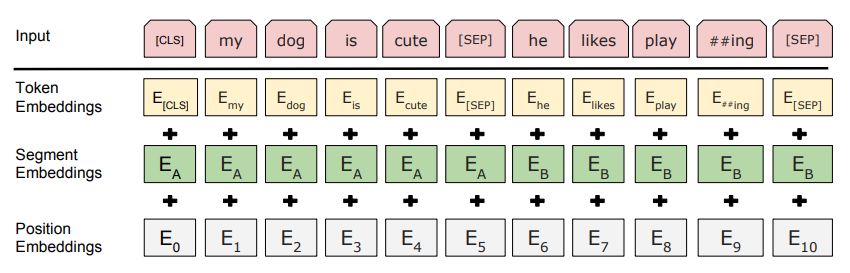
从框图上可以看到,输入序列是各token的embedding。在Transfomer中,这种嵌入由word embedding加上positional embedding而来。而在BERT中,还要额外加上一个segment embedding,用于指示各个token属于输入的第几个句子。这是因为有的nlp任务是输入一对句子的,需要借此加以区分。而且,positional embedding也不是沿用三角函数,三种embedding都是学习出来的。
另外,一开始的token,除了要在一开始添加一个起始标志[CLS]之外,还要在不同句子的过渡位置插一个[SEP]标志(如果有多句子的话)。
迁移策略
BERT是一个预训练模型,所以我们要怎么拿过来用呢?官方为我们提供了各种任务的应用方法。
首先,NLP的下游任务可以分为4类:
- 句子关系判断:识别蕴含(entailment)、识别语义相似等
- 分类任务:文本分类、情感计算等
- 序列标注:分词、实体识别、语义标注等
- 生成式任务:机器翻译、文本摘要等
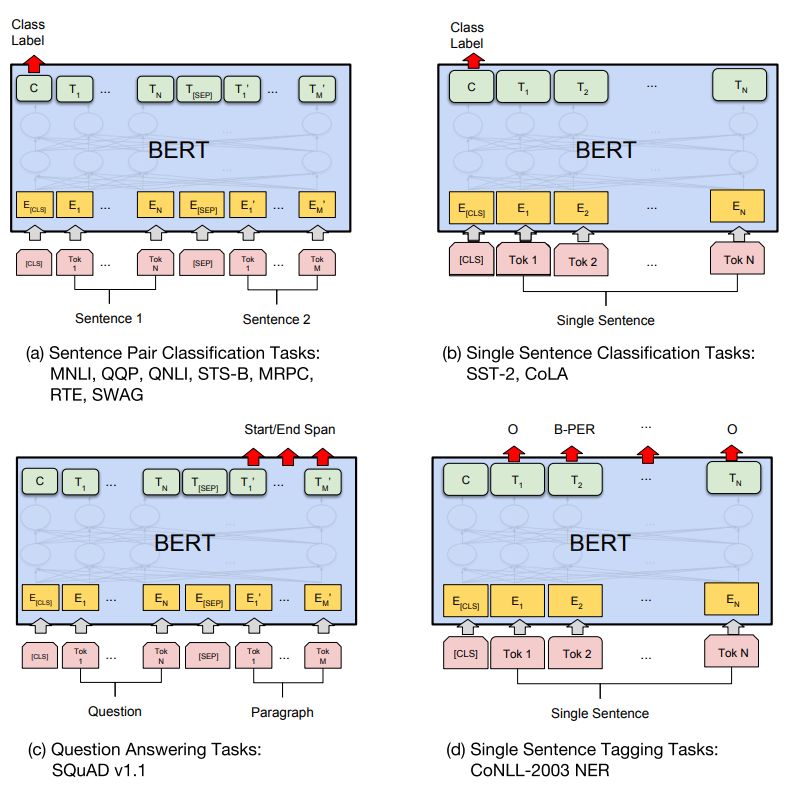
图中 (a) 解决的是句子关系判断问题,MultiNLI(识别蕴含,M推理出N,蕴含/矛盾/中立),QQP(识别语义相似),QNLI(识别是否回答了问题),STS-B(识别语义相似),MRPC(识别语义等价,微软)、RTE(识别蕴含,小数据),SWAG(识别回答问题,大数据)。
(b) 解决的是分类任务,SST-2(情感计算,斯坦福),CoLA(句子语言性判断,是否能成句)。
(c) 解决的是序列标注任务,SQuAD(判断回答的起始和结束时刻,斯坦福问答数据集,从phrase中选取answer)。
(d) 解决的是序列标注任务,NER(命名实体识别)。
总的来说 (a) 和 (b) 都是分类任务,差别在于输入的是一个句子还是一对句子。这类任务,只需通过在第一个token(即[CLS]标志)的特征序列送入全连接层即可获取识别结果。(c) 和 (d) 都是序列标注任务,这类则在多个token的特征序列送入全连接层,获取各自的标注结果。可以看到,目前只有生成式任务还没有被ko。
p.s. 大名鼎鼎的GLUE任务集则包含了MultiNLI、QQP、QNLI、STS-B、MRPC、RTE、WNLI(也是识别蕴含)、SST-2、CoLA。
预训练方法
常见的预训练方法一般是给前面的序列去预测下一个token(像是GPT)。而BERT就提出了两个比较有意思的训练任务 —— Masked LM 和 Next Sentence Prediction。
Masked LM
为了实现模型的双向,就不能一直给定前面预测后面,于是作者提出了一个trick。在训练过程中,随机mask掉15%的token,即把相应位置的token替换成一个[MASK]标识,而任务的目标就是要去恢复这个句子(包含MASK的词),而损失函数只考虑了MASK位置的预测值,忽视掉非masked的值。这样,MASK的词可前可后,就实现了模型的双向性。
由此也衍生出了一个问题,就是在实际预测的时候是不会碰到[MASK]的,用了太多[MASK]就容易影响到模型。所以作者又用了个小技巧,选中了要mask的token后,其中10%的token会被替代成其他token,10%的token不替换,剩下的80%才被替换为[MASK]。
Next Sentence Prediction
由于nlp中存在需要输入两个句子的句子关系判断任务,所以需要增设一个让模型理解句子之间关系的任务,于是Next Sentence Prediction应运而生。具体而言,就是输入两个句子,由模型来判断这两个句子是不是连续的上下句。其中,为了保持样本平衡性,选了50%的连续的正样本,再随机选50%的无关的负样本。其实这个任务和seq2seq的任务有点异曲同工之妙,只是从单词级别变到了句子级别。举个例子:
正样本:今天[MASK](天气)真好,正好我们[MASK](出去)吃饭吧。
负样本:今天[MASK](天气)真好,[MASK](我)吃饱了。
总结
其实BERT模型除了提出这两种训练方法外,大量的数据肯定对这个预训练模型有很强的作用,不过一般人没这种计算资源…所以还是很感谢谷歌开源出来的预训练模型,可以很方便的使用并达到非常好的效果。在使用时,如果需要用到自己的数据库上,要么就是完全自己写然后导入BERT模型,要么可以直接使用官方的代码,如run_glue.py,只需要修改数据的预处理,定义好新的类,然后指定类别数等参数,就可以直接使用了。
参考文献
https://www.cnblogs.com/rucwxb/p/10277217.html
https://zhuanlan.zhihu.com/p/46652512

