
前言
本文汇总了一些常见或不常见的语音特征,持续更新中。
特征汇总
韵律特征(prosodic feature)
包含语音中音高、语调、能量、节奏变化等重要信息,表现为人昕觉系统感知到的“抑扬顿挫”,在语音信号处理的许多领域都有应用。基音频率、语速、能量等都是常用的韵律学特征。
基音频率(fundamental frequency, F0)是指发浊音时声带振动的频率,简称基频。人发声过程中来自肺部的气流冲击声门,形成一系列准周期的气流脉冲,经过声道的谐振及唇齿辐射最终形成语音信号,故浊音波形呈现一定的准周期性,这个周期就是基音周期,它和基频成倒数关系。基频变化范围很大,受性别、年龄、情绪等多种因素的影响。一般而言,男性的基频范围是135-185Hz,女性在260-350Hz之间。
基频检测方法主要有三类:1、时域:基于过零率,自相关等,最好的是YIN/PYIN算法。2、频域:倒谱,谐波,最佳梳妆滤波器等。3、统计方法:最大似然,rnn,HMM等都有。
语速(speaking rate) 特征表达了讲话速度的快慢,可以定义为单位时间内发音的词汇(或者音节)个数。语速受文化、环境、思维和表达能力多种因素的影响。和语速密切相关的因素还有停顿,是否考虑语段中的停顿对语速的计算数值有明显影响。
能量(energy)是与语音音量(或者说幅度)相关的声学特征。能量特征包含丰富的情感信息,比如人在悲伤时语音的能量通常会比较低。很早以前 vad(voice active detection) 中有一种检测语音方法:能量大的是语音,能量小的是噪声。当然,这种vad局限性非常大,用途很窄。
过零率 (zero-crossing rate) 核心点是计算信号跨越零点的次数,早期用于vad,判别语音和噪声,局限性也较大。
谱特征(spectral feature)
含义相对宽泛,通常包含了语音信号的频谱、功率谱、倒频谱、频谱包络等特征。由于语音是短时平稳信号,所以通常用短时傅里叶变化对语音做分析,这样产生的特征能反映语音的短时特性。
梅尔倒谱系数(Mel-frequency Cepstral Coefficients, MFCC)
原理:根据人耳听觉机理的研究发现,人耳对不同频率的声波有不同的听觉敏感度。从200HZ到5000HZ对语音的清晰度影响最大。两个响度不等的声音作用于人耳时,则响度较高的频率成分的存在会影响到对响度较低的频率成分的成分,使其变得不易察觉,这种现象称为掩蔽效应。由于频率较低的声音在内耳蜗基底膜上行波传递的距离大于频率较高的声音,故一般来说,低音容易掩蔽高音,而高音掩蔽低音较困难。在低频处的声音掩蔽临界带宽较高频要小。所以从低频到高频这一频带内按临界带宽的大小由密到疏安排一组带通滤波器,对输入信号进行滤波。
它是Mel标度频率域提取出来的倒谱系数,常用在语音识别和说话人识别领域。MFCC使用一组从低频到高频由密到疏交叠排列的三角形带通滤波器构建特征,这和人耳的听觉特性相符。出于计算复杂度的考虑,实际使用中MFCC系数通常取12-16阶。
Bark谱 (Bark Spectrogram)
Bark谱与MFCC,Mel谱非常相似,都是将线性谱映射到非线性谱上的表征,而且都是低频带宽低,高频带宽高。
上世纪,研究者发现人耳结构对24个频点产生共振,根据这一理论,Eberhard Zwicker在1961年针对人耳特殊结构提出:信号在频带上也呈现出24个临界频带,分别从1到24。这就是Bark域。
CQT (Constant Q Transform)
恒Q变换,也是一种非线性映射。指中心频率按指数规律分布,滤波带宽不同、但中心频率与带宽比为常量Q的滤波器组。与傅立叶变换不同,它频谱的横轴频率不是线性的,而是基于log2为底的,并且可以根据谱线频率的不同该改变滤波窗长度,以获得更好的性能。由于符合乐理常用在音乐中。
乐理里,所有的音都是由若干八度的12平均律共同组成的,12个半音等于一个八度,一个八度的跨度等于频率翻倍,所以一个半音等于2^(1/12)倍频。因此,音乐中的音调呈指数型跨度的,而CQT就很好的模拟了这种非线性度,以 log2 为底的非线性频谱。
共振峰(formant)
是基频对应的整数次频率成分,用来反映人的声道物理特性。声道可以看成具有非均匀截面的声管,当准周期脉冲激励进入声道时会带动空气共振,产生一组共振频率,称为共振峰频率或简称共振峰。共振峰特征包括共振峰频率和频带宽度等。共振峰信息包含在语音频谱包络之中,在语音信号合成、语音识别中都有广泛应用。研究中常用的通常是前三个共振峰。共振峰的包络,位置,相邻的距离共同形成了音色特征。共振峰之间距离近听起来则偏厚粗,之间距离远听起来偏清澈。在男声变女声的时候,除了基频的移动,还需要调整共振峰,包括包络,距离等。否则将会丢失音色信息。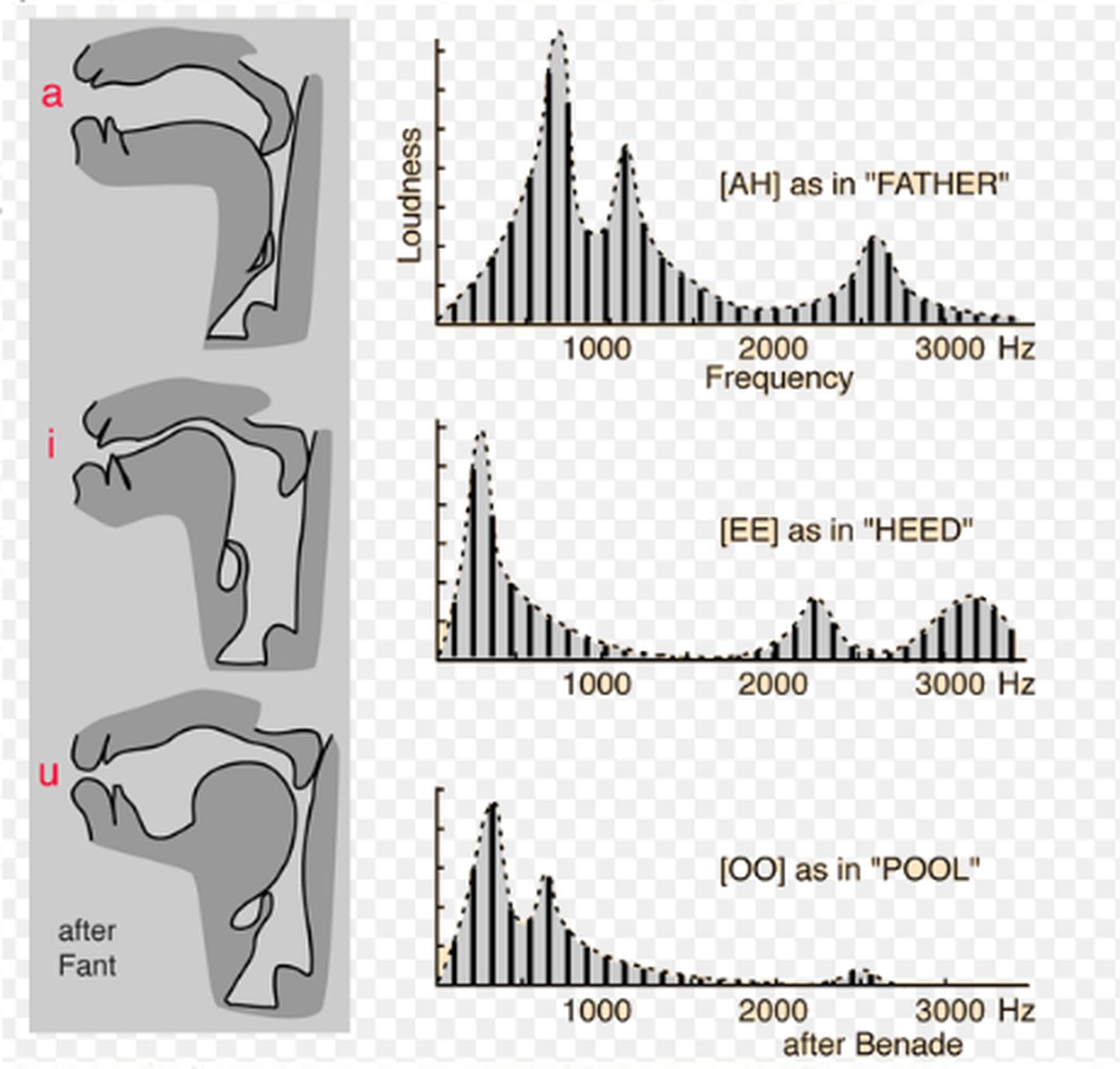
一个浊音用三个共振峰来表示,一个共振峰的频谱特性其实可以用一个GMM来建模拟合的,也就是说一个浊音是需要三个GMM来建模拟合,所以HMM需要三个状态也是这样来的;而非文本音素要用五个HMM状态,也是因为清音比较复杂,需要五个共振峰才能较好表示。
线性预测系数(Linear Predictive Coefficients, LPC) 是指对语音信号值进行线性预测的一组系数。具体而言,LPC是用若干个过去值的加权线性组合来逼近当前值,其中的权值即为线性预测系数。LPC能精确、便捷地表征语音短时能量的谱包络,并且能有效地估计基频、共振峰等语音参数。
Teager能量算子(Teager Energy Operation, TEO)是H.M.Teager提出的用以跟踪信号瞬时能量的非线性算子 。Teager指出,一个信号的能量不仅与它的幅度相关,而且与它的振动频率相关。TEO计算简单且时间分辨率高,对于解调信号效果很好。
声门波(glottal wave)反应了声门特性,是一种源特征。声门波可以获得比较准确的声道响应,它蕴含情感信息,对情感识别有一定作用。也有文章显示,从声门波的幅值提取出的特征,如NormalisedAmplitude Quotient (NAQ), the Quasi Open-Quotient (QOQ)等。
特征集汇总
GeMAPS特征集
GeMAPS特征集总共62个特征,这62个都是HSF特征,是由18个LLD特征计算得到。下面先介绍18个LLD特征,然后介绍62个HSF特征。这里只简单介绍每个特征的概念,不涉及具体计算细节。
- 18个LLD特征包括6个频率相关特征,3个能量/振幅相关特征,9个谱特征。
6个频率相关特征包括:Pitch(log F0,在半音频率尺度上计算,从27.5Hz开始);Jitter(单个连续基音周期内的偏差,偏差衡量的是观测变量与特定值的差,如果没有指明特定值通常使用的是变量的均值);前三个共振峰的中心频率,第一个共振峰的带宽。3个能量/振幅的特征包括:Shimmer(相邻基音周期间振幅峰值之差),Loudness(从频谱中得到的声音强度的估计,可以根据能量来计算),HNR(Harmonics-to-noise)信噪比。9个谱特征包括,Alpha Ratio(50-1000Hz的能量和除以1-5kHz的能量和),Hammarberg Index(0-2kHz的最强能量峰除以2-5kHz的最强能量峰),Spectral Slope 0-500 Hz and 500-1500 Hz(对线性功率谱的两个区域0-500 Hz和500-1500 Hz做线性回归得到的两个斜率),Formant 1, 2, and 3 relative energy(前三个共振峰的中心频率除以基音的谱峰能量),Harmonic difference H1-H2(第一个基音谐波H1的能量除以第二个基音谐波的能量),Harmonic difference H1-A3(第一个基音谐波H1的能量除以第三个共振峰范围内的最高谐波能量)。 - 对18个LLD做统计,计算的时候是对3帧语音做symmetric moving average。首先计算算术平均和coefficient of variation(计算标准差然后用算术平均规范化),得到36个统计特征。然后对loudness和pitch运算8个函数,20百分位,50百分位,80百分位,20到80百分位之间的range,上升/下降语音信号的斜率的均值和标准差。这样就得到16个统计特征。上面的函数都是对voiced regions(非零的F0)做的。对Alpha Ratio,Hammarberg Index,Spectral Slope 0-500 Hz and 500-1500 Hz做算术平均得到4个统计特征。另外还有6个时间特征,每秒loudness峰的个数,连续voiced regions(F0>0)的平均长度和标准差,unvoiced regions(F0=0)的平均长度和标准差,每秒voiced regions的个数。36+16+4+6得到62个特征。
eGeMAPS特征集
(1)eGeMAPS是GeMAPS的扩展,在18个LLDs的基础上加了一些特征,包括5个谱特征:MFCC1-4和Spectral flux(两个相邻帧的频谱差异)和2个频率相关特征:第二个共振峰和第三个共振峰的带宽。
(2)对这扩展的7个LLDs做算术平均和coefficient of variation(计算标准差然后用算术平均规范化)可以得到14个统计特征。对于共振峰带宽只在voiced region做,对于5个谱特征在voiced region和unvoiced region一起做。
(3)另外,只在unvoiced region计算spectral flux的算术平均,然后只在voiced region计算5个谱特征的算术平均和coefficient of variation,得到11个统计特征。
(4)另外,还加多一个equivalent sound level 。
(5)所以总共得到14+11+1=26个扩展特征,加上原GeMAPS的62个特征,得到88个特征,这88个特征就是eGeMAPS的特征集。
ComParE特征集
(1)ComParE,Computational Paralinguistics ChallengE,是InterSpeech上的一个挑战赛,从13年至今(2018年),每年都举办,每年有不一样的挑战任务。
(2)从13年开始至今(2018年),ComParE的挑战都会要求使用一个设计好的特征集,这个特征集包含了6373个静态特征,是在LLD上计算各种函数得到的,称为ComParE特征集。
(3)可以通过openSmile开源包来获得,另外前面提到的eGeMAPS也可以用openSmile获得。
五:2009 InterSpeech挑战赛特征
(1)前面说的6373维特征集ComparE是13年至今InterSpeech挑战赛中用的。(2)有论文还用了09年InterSpeech上Emotion Challenge提到的特征,总共有384个特征,计算方法如下。
(3)首先计算16个LLD,过零率,能量平方根,F0,HNR(信噪比,有些论文也叫vp,voice probability 人声概率),MFCC1-12,然后计算这16个LLD的一阶差分,可以得到32个LLD。
(4)对这32个LLD应用12个统计函数,最后得到32x12 = 384个特征。
(5)同样可以通过openSmile来获得。
BoAW
(BoAW,bag-of-audio-words,是特征的进一步组织表示,是根据一个codebook对LLDs做计算得到的。这个codebook可以是k-means的结果,也可以是对LLDs的随机采样。在论文会看到BoAW特征集的说法,指的是某个特征集的BoAW形式。比如根据上下文“使用特征集有ComparE和BoAW”,可以知道,这样的说法其实是指原来的特征集ComparE,和ComparE经过计算后得到的BoAW表示。可通过openXBOW开源包来获得BoAW表示。
YAAFE:
使用YAAFE库提取到的特征,具体特征见YAAFE主页。
参考
https://www.zhihu.com/question/24190826
https://blog.csdn.net/weixin_42300798/article/details/113627332

